

OS Part 4: CPU Scheduling ⏳

That Indian Dev 🇮🇳
Scheduling algorithms are crucial components of operating systems that determine the order in which processes are allocated CPU time. These algorithms play a vital role in optimizing resource utilization, enhancing system performance, and ensuring fairness among processes.
Some important terms related to process scheduling:
Throughput: Throughput refers to the number of processes completed within a unit of time. It measures the system's efficiency in executing and completing processes.
Arrival Time (AT): The arrival time denotes the moment when a process enters the ready queue, indicating the time it arrives for execution.
Burst Time (BT): Burst time represents the duration required by a process to complete its execution, from start to finish.
Turnaround Time (TAT): Turnaround time is the total duration a process spends in the system, including waiting time and execution time. It is calculated as the difference between the completion time (CT) and the arrival time (AT) of the process (TAT = CT - AT).
Waiting Time (WT): Waiting time refers to the time duration a process spends waiting in the ready queue, waiting for its turn to be allocated CPU time. It is calculated by subtracting the burst time (BT) and the turnaround time (TAT) from the waiting time (WT = TAT - BT).
Response Time: Response time measures the duration between a process entering the ready queue and obtaining CPU execution for the first time. It indicates the system's initial responsiveness to the process's request.
Completion Time (CT): Completion time signifies the time taken from when a process starts execution until it terminates, marking the completion of its execution.
Types of Scheduling Algorithms
Non-Preemptive Scheduling Algorithm: Non-preemptive scheduling, also known as cooperative scheduling, allows a process to run until it voluntarily relinquishes the CPU or completes its execution. Once a process gains control of the CPU, it continues executing until it finishes or explicitly requests a yield or sleep operation. Non-preemptive algorithms are often simpler to implement since they don't require interrupting a running process.
Preemptive Scheduling Algorithm: Preemptive scheduling involves forcibly interrupting a running process and allocating the CPU to another process with higher priority. This type of scheduling allows the operating system to control and prioritize processes more effectively, especially in multi-tasking environments. The ability to preempt running processes adds complexity to the scheduling algorithm but provides finer-grained control over resource allocation.
First Come First Serve (FCFS)
The First Come First Serve (FCFS) scheduling algorithm is one of the simplest and most straightforward approaches used in operating systems for process scheduling. It operates on the principle of serving processes in the order they arrive, where the first process that arrives is the first to be executed. FCFS is a non-preemptive scheduling algorithm, meaning once a process starts executing, it continues until it completes or voluntarily relinquishes the CPU.
Working Principle
When a process enters the system, it is added to the end of the ready queue, forming a line of processes waiting for execution. The operating system assigns the CPU to the process at the front of the queue. The process then runs until it finishes or gets blocked, such as when waiting for I/O operations to complete. Only when the current process completes or enters a blocked state does the operating system move on to the next process in the queue.
Convoy Effect
The convoy effect occurs when a long process holds up the execution of other shorter processes that are queued behind it. As the long process monopolizes the CPU for an extended period, other processes have to wait, even if they require significantly less time to complete. This delay results in decreased system throughput and overall performance.
Shortest Job First (SJF) [Non-preemtive]
The Shortest Job First (SJF) scheduling algorithm is a non-preemptive approach used in operating systems for process scheduling. It aims to minimize the average waiting time by prioritizing the execution of processes with the shortest expected processing time.
Working Principle
The SJF algorithm works on the principle of selecting the shortest job from the available processes in the ready queue for execution. When a process enters the system, the operating system compares its expected total processing time (or burst time) with the remaining burst times of other processes in the queue. The process with the shortest burst time is selected for execution. Once a process starts executing, it continues until it completes its execution or voluntarily relinquishes the CPU.
Shortest Job First (SJF) [Preemtive]
The Shortest Job First (SJF) scheduling algorithm, also known as Shortest Remaining Time First (SRTF) in its preemptive form, is a dynamic approach used in operating systems for process scheduling. It prioritizes the execution of processes based on their expected remaining burst time, allowing shorter jobs to be executed first and promoting efficient resource utilization.
Working Principle
In the preemptive version of SJF, known as SRTF, the operating system continuously evaluates the remaining burst time of all processes in the ready queue and selects the process with the shortest remaining time for execution. If a new process with a shorter burst time arrives or a running process is preempted, the CPU is allocated to the process with the shortest remaining time. When a process enters the system, it is added to the ready queue. If the arriving process has a shorter burst time than the currently executing process, the operating system interrupts the running process and schedules the new process to execute. This preemptive behaviour allows for a more efficient allocation of system resources and ensures that shorter jobs are executed as soon as they become available.
Priority Scheduling [Non-preemptive]
The Priority Scheduling algorithm is a non-preemptive process scheduling approach used in operating systems, where each process is assigned a priority value, and the CPU is allocated to the process with the highest priority. This algorithm ensures that higher-priority processes are executed before lower-priority ones, allowing for efficient resource allocation based on process importance.
Working Principle
In Priority Scheduling (non-preemptive), each process is assigned a priority value, typically represented as an integer or a priority level. The higher the priority value, the higher the priority of the process. When a process enters the system, it is placed in the ready queue based on its priority. The CPU is then allocated to the process with the highest priority, and it continues executing until it completes or voluntarily yields the CPU. If multiple processes have the same priority, a simple tie-breaking strategy, such as First Come First Serve (FCFS), can be used to determine the execution order among those processes with equal priorities.
Priority Scheduling [Preemptive]
The Priority Scheduling algorithm in its preemptive form is a process scheduling approach used in operating systems. It assigns a priority value to each process and allows the CPU to be allocated to the process with the highest priority. In preemptive Priority Scheduling, higher-priority processes can interrupt lower-priority processes during their execution, enabling efficient resource utilization and responsiveness.
Working Principle
In preemptive Priority Scheduling, each process is assigned a priority value, typically represented as an integer or a priority level. The higher the priority value, the higher the priority of the process. When a process enters the system or a higher-priority process becomes ready, the CPU is allocated to the process with the highest priority. If a process with a higher priority arrives or a running process is preempted, the currently running process is interrupted, and the CPU is allocated to the higher-priority process. If multiple processes have the same priority, a tie-breaking strategy, such as First Come First Serve (FCFS), can be employed to determine the execution order among those processes with equal priorities.
Ageing
Ageing is a technique used in priority scheduling algorithms, both preemptive and non-preemptive versions, to address the issue of indefinite waiting or starvation for lower-priority jobs. The concept involves gradually increasing the priority of processes that have been waiting for a long time. By periodically boosting the priority of waiting processes, ageing ensures that lower-priority jobs eventually receive the opportunity to execute, preventing indefinite delays and promoting fairness in resource allocation. This approach helps balance the scheduling algorithm and prevents lower-priority processes from being neglected indefinitely, enhancing overall system performance and responsiveness.
Round Robin Scheduling (RR)
Round Robin (RR) scheduling is a popular preemptive process scheduling algorithm used in operating systems. It is designed to provide fair CPU time allocation among multiple processes by dividing the CPU execution time into fixed time intervals called time slices or quantum. RR ensures that no single process monopolizes the CPU for an extended period, promoting equitable resource utilization.
Working Principle
In Round Robin scheduling, each process is assigned a time slice, typically ranging from a few milliseconds to tens or hundreds of milliseconds. The processes are placed in a circular queue known as the ready queue. The CPU is allocated to the first process in the queue for its time slice. If the process completes its execution within the time slice, it is removed from the queue. Otherwise, it is temporarily moved to the end of the queue, and the next process in the queue is allocated the CPU for its time slice. This cycle continues until all processes complete their execution or are blocked. If a process arrives after its time slice expires, it is placed at the end of the ready queue and waits for its turn to be allocated to the CPU.
Multi-Level Queue Scheduling (MLQ)
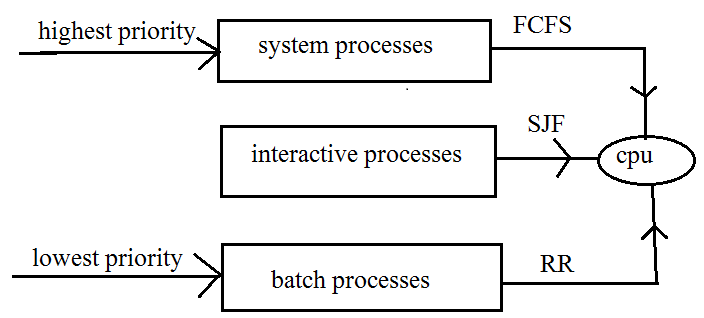
Multi-level queue scheduling is a process scheduling algorithm that divides the ready queue into multiple sub-queues based on process properties such as priority, memory size, process type, or other relevant factors. Each sub-queue has its scheduling algorithm to handle process dispatching.
Working Principle
Sub-queues based on Priority: The ready queue is divided into multiple sub-queues based on priority levels. Each sub-queue represents a different priority range, such as high, medium, and low.
Permanent Assignment to Sub-queues: Each process is permanently assigned to a specific sub-queue based on a property of the process, such as its priority, memory requirements, size, or type. This assignment is inflexible, meaning that a process remains in its assigned sub-queue throughout its execution.
Different Scheduling Algorithms: Each sub-queue is associated with its own scheduling algorithm. For example, the high-priority sub-queue might use Shortest Job First (SJF), the medium-priority sub-queue might use Round Robin, and the low-priority sub-queue might use First-Come-First-Serve (FCFS).
Categories of Processes: Processes are categorized into different types,
System Processes: created by the operating system and given the highest priority
Interactive Processes: foreground processes that require user input or involve I/O operations
Batch Processes: background processes that run silently without user interaction
Fixed Priority Preemptive Scheduling: Scheduling among the different sub-queues is implemented as fixed-priority preemptive scheduling. This means that the sub-queues with higher priority have an absolute priority over the lower-priority sub-queues. For example, the foreground queue always has priority over the background queue.
Preemption of Lower-Priority Processes: If an interactive process arrives while a batch process is executing, the batch process is preempted to allow the interactive process to execute. This ensures that foreground processes receive immediate attention and do not experience excessive delays.
Starvation and Convoy Effect: One limitation of multi-level queue scheduling is that lower-priority processes may suffer from starvation. This occurs when all processes in higher-priority sub-queues need to complete before processes in lower-priority sub-queues are scheduled. This can lead to delays for lower-priority processes and the convoy effect, where a long process in a lower-priority sub-queue holds up other processes.
Multi-Level Feedback Queue Scheduling (MLFQ)

Multi-level feedback queue scheduling is an enhanced version of multi-level queue scheduling that allows processes to move between sub-queues based on their behaviour and resource requirements. It addresses some of the limitations of MLQ, such as starvation and inflexibility.
Working Principle
Dynamic Movement between Sub-queues: In MLFQ, processes can move between sub-queues based on their characteristics, particularly their CPU burst time (BT). If a process uses too much CPU time, it will be moved to a lower-priority sub-queue. This allows I/O bound and interactive processes to remain in higher-priority sub-queues.
Ageing and Prevention of Starvation: MLFQ incorporates ageing, where a process that waits for too long in a lower-priority sub-queue may be moved to a higher-priority sub-queue. This prevents starvation and ensures that processes waiting for an extended period get an opportunity to execute.
Reduced Starvation: MLFQ is designed to reduce the occurrence of starvation compared to MLQ. The dynamic movement of processes between sub-queues based on their behaviour helps distribute CPU time more evenly and prevents long-term delays for lower-priority processes.
Flexibility and System Design: MLFQ offers flexibility and can be configured to match specific system design requirements. It allows system administrators to adjust the parameters, such as the number of sub-queues, time quantum for each sub-queue, and criteria for movement between sub-queues, to optimize system performance and responsiveness.
In conclusion, CPU scheduling algorithms are crucial components of operating systems that optimize resource utilization and enhance system performance. The various algorithms discussed, including FCFS, SJF, Priority Scheduling, RR, MLQ, and MLFQ, provide different approaches to process allocation, minimizing waiting time and ensuring fairness. Understanding these algorithms is essential for designing efficient operating systems. In the next part, we will delve into the concept of threads, lightweight execution paths within a process, and explore how they enable parallelism, resource sharing, and efficient multitasking in operating systems.




